FuriosaAI verzichtet auf GPUs und setzt auf 2-nm Broadcom-Inferenzchip mit HBM4/E-Bandwidth
FuriosaAI und Broadcom haben sich zur Entwicklung eines Hochleistungs-AI-Beschleunigerchips mit next-Generation HBM4/E-Speicher verbunden.

Kurzfassung
Warum das wichtig ist
- FuriosaAI und Broadcom haben sich zur Entwicklung eines Hochleistungs-AI-Beschleunigerchips mit next-Generation HBM4/E-Speicher verbunden.
- FuriosaAI und Broadcom haben eine strategische Partnerschaft eingegangen, um gemeinsam einen Hochleistungs-AI-Beschleunigerchip zu entwickeln.
- Im Mittelpunkt dieses Projekts steht der Einsatz nächsten Generation, dem HBM4/E, der eine deutlich erhöhte Bandbreite für rechenintensive Anwendungen verspricht.
Die angekündigte dritte Generation des AI-Beschleunigers zweiten Generation der RNGD-Plattform.
Diese Vorgängerversion wird derzeit in der Massenfertigung auf der 5-nm-Prozess-Technologie der zweiten Generation ist als 180-Watt-Modul konzipiert, das über einen PCIe-Slot angeschlossen wird, und richtet sich spezifisch an Arbeitslasten für große Sprachmodelle (LLM) sowie für Agentic-AI-Systeme.
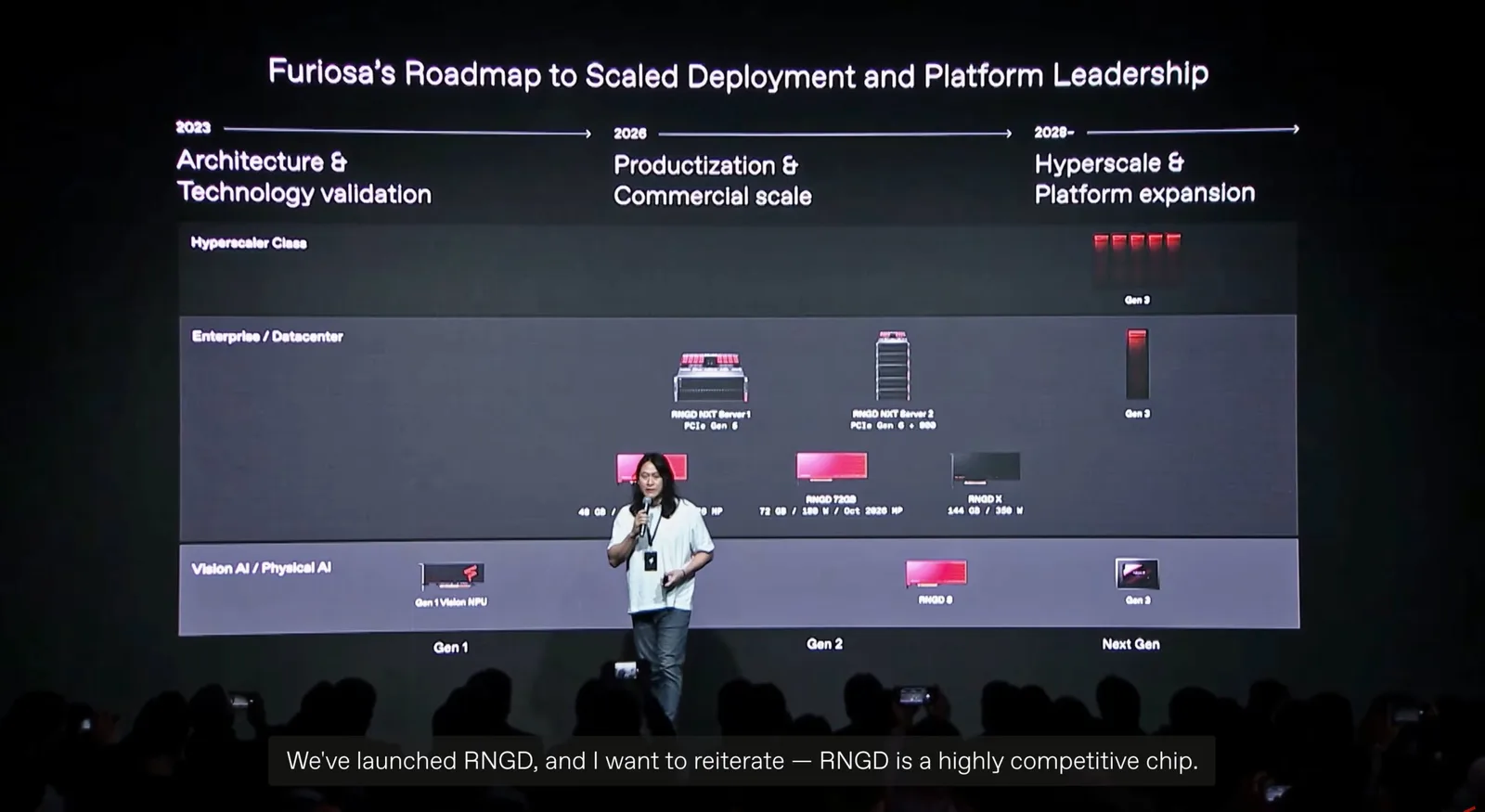
Das neue, dritte Generation-Design wird sich ausschließlich auf den Bereich der AI-Inferenz konzentrieren. Diese Ausrichtung resultiert aus der weiterhin extrem hohen Nachfrage nach Agentic-AI-Lösungen.
Der neue Chip wird zudem eine 2-nm-Chiplet-Architektur aufweisen und den HBM4/E-Speicher unterstützen, um die Leistungsfähigkeit für massive KI-Rechencluster zu gewährleisten.
Quelllink
Wccftech - Originalartikel oeffnenThema weiterverfolgen
Interne Verlinkung
Im Kontext weiterlesen
Diese weiterfuehrenden Links verbinden das Thema mit relevanten Archivseiten, Schlagwoertern und inhaltlich nahen Artikeln.
Technologie Archiv
Weitere Meldungen aus derselben Hauptkategorie.
Mehr von Wccftech
Alle veroeffentlichten Inhalte derselben Quelle im Archiv.
Wissenschaftler nutzen Quantenverschränkung zur Erzeugung perfekter Zufallszahlen
Redaktionell verwandter Beitrag aus dem selben Themenumfeld.
Valve erhöht Steam Deck OLED-Preise: 512GB-Modell für 789 Dollar, 1TB-Version für 949 Dollar
Redaktionell verwandter Beitrag aus dem selben Themenumfeld.
Quellenprofil
Quelle und redaktionelle Angaben
- Quelle
- Wccftech
- Originaltitel
- FuriosaAI Ditches GPU Playbook For 2 nm Broadcom-Built Inference Chip, Claims HBM4/E Bandwidth Beats Even The Most Efficient GPUs
- Canonical
- https://wccftech.com/furiosaai-ditches-gpu-playbook-for-2nm-broadcom-built-inference-chip-claims-hbm4-e-bandwidth-beats-gpus/
- Quell-URL
- https://wccftech.com/furiosaai-ditches-gpu-playbook-for-2nm-broadcom-built-inference-chip-claims-hbm4-e-bandwidth-beats-gpus/
Aehnliche Inhalte
Verwandte Themen und interne Verlinkung
Weitere Artikel aus aehnlichen Themenfeldern, damit Leser direkt im selben Kontext weiterlesen koennen.

Wissenschaftler nutzen Quantenverschränkung zur Erzeugung perfekter Zufallszahlen
Forscher am ETH Zürich haben ein Verfahren entwickelt, mit dem sie mithilfe der Quantenphysik „perfekte" Zufallszahlen erzeugen können.
27.05.2026
Live Redaktion
Valve erhöht Steam Deck OLED-Preise: 512GB-Modell für 789 Dollar, 1TB-Version für 949 Dollar
Kopieren Sie den Link
27.05.2026
Live Redaktion
Apple führt heimliche Schutzmaßnahmen für Nutzer durch, opfert Milliarden an Jahresgewinnen und wird dennoch als gierig bezeichnet.
Im Zentrum steht der App Store, ein Repository mit Millionen , die Kategorien wie Produktivität, Unterhaltung, Gaming, Finanzen, soziale Medien und weitere untert
27.05.2026
Live Redaktion
Hackern nutzen Grandoreiro-Malware zum Angriff auf portugiesische Banken und lateinamerikanische Unternehmen
Ein seit 2016 still operierender Bankentroyan rückt erneut in den Fokus der Öffentlichkeit.
27.05.2026
Live Redaktion