AMD vLLM-ATOM-Plugin beschleunigt DeepSeek-R1, Kimi-K2 und gpt-oss-120B auf Instinct MI350/MI400
AMD hat einen neuen Plugin namens vLLM-ATOM vorgestellt, der AI-LLMs beschleunigt und dabei die Instinct-MI350- und MI400-GPUs untersttzt.

Kurzfassung
Warum das wichtig ist
- AMD hat einen neuen Plugin namens vLLM-ATOM vorgestellt, der AI-LLMs beschleunigt und dabei die Instinct-MI350- und MI400-GPUs untersttzt.
- Das vLLM-ATOM ist ein speziell entwickeltes Plugin, das darauf abzielt, die Inferenzleistung bei verschiedenen AI-LLMs zu verbessern.
- Es ist um AMDs High-Performance-Instinct-GPU-Beschleuniger wie die MI350- und MI400-Serie herum konzipiert und kann sowohl als eigenstndiger Inferenzserver als auch durch nahtlose Integration als Plugin-Backend betrieben werden.
SvyTech-Check
Redaktionelle Einordnung
Kernpunkt
AMD hat einen neuen Plugin namens vLLM-ATOM vorgestellt, der AI-LLMs beschleunigt und dabei die Instinct-MI350- und MI400-GPUs untersttzt.
Warum relevant
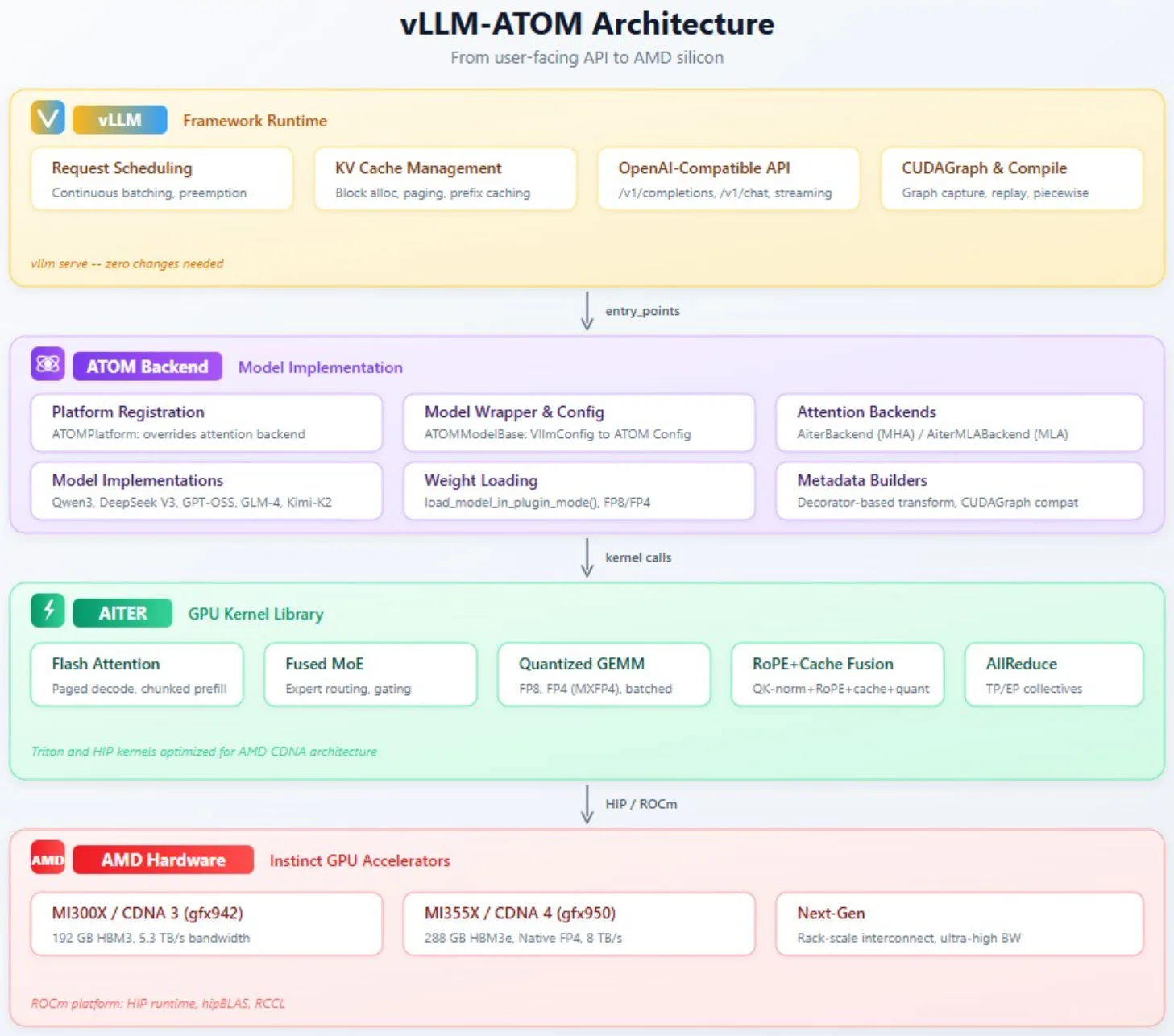
Zu den Hauptmerkmalen: Die Architektur drei Ebenen: Hinsichtlich der Modelluntersttzung untersttzt das vLLM-ATOM-Plugin sowohl AI-LLMs als auch VLMs ber eine einheitliche Serving-Pipeline.
Einordnung
SvyTech ordnet die Meldung aus Wccftech als Teil des Themenfelds Technologie ein und verweist auf den Originalartikel, damit Leser Fakten, Quelle und Kontext nachvollziehen koennen.
Zu den Hauptmerkmalen: Die Architektur drei Ebenen: Hinsichtlich der Modelluntersttzung untersttzt das vLLM-ATOM-Plugin sowohl AI-LLMs als auch VLMs ber eine einheitliche Serving-Pipeline. Im Folgenden finden Sie die vollstndige Liste: Hinweis: vLLM-ATOM beweist, dass hardware-spezifische Optimierungen und Framework-Kompatibilitt nicht unvereinbar sind.
Durch die Nutzung des vLLM-Plugin-Mechanismus aus der Box heraus bietet ATOM native Kernel-Optimierungen für AMD, darunter fused attention, quantisierte GEMM und optimiertes MoE-Routing, während es das gesamte Funktionsset, auf das produktionsreife LLM-Bereitstellungen angewiesen sind.
Über die unmittelbaren Leistungssteigerungen hinaus dient die Architektur des Plugins als entscheidende Testumgebung für Hard- und Software-Innovationen: Optimierungen, die im Plugin-Modus, werden schrittweise in den nativen ROCm-Backend übernommen und kommen der gesamten ROCm- sowie Open-Source-LLM-Community zugute.
Quellenprofil
Quelle und redaktionelle Angaben
- Quelle
- Wccftech
- Canonical
- https://wccftech.com/amd-vllm-atom-plugin-supercharges-deepseek-r1-kimi-k2-gpt-oss-120b-ai-llm-inference-on-instinct-mi350-mi400/
- Quell-URL
- https://wccftech.com/amd-vllm-atom-plugin-supercharges-deepseek-r1-kimi-k2-gpt-oss-120b-ai-llm-inference-on-instinct-mi350-mi400/
Aehnliche Inhalte
Verwandte Themen und interne Verlinkung
Weitere Artikel aus aehnlichen Themenfeldern, damit Leser direkt im selben Kontext weiterlesen koennen.

US Air Force stellt neues provisorisches Air Force One-Flugzeug vor
Die US-Luftwaffe hat auf der Joint Base Andrews ein , modifiziertes Boeing-747-8-Flugzeug als vorübergehende Lösung für die Präsidentenflotte vorgestellt, da die Lieferung der ursprünglich geplanten VC-25B-Modelle durch Lieferkettenprobleme und Budgetüberschreitungen verzögert ist. Dieses provisorische Fahrzeug, das mit einer maximalen Geschwindigkeit 315 Metern pro Sekunde und einer Nutzlast 124 Tonnen ausgestattet ist, soll die Sicherheits- und Kommunikationsstandards erfüllen, bis die für 2028 erwarteten neuen VC-25B-Flugzeuge einsatzbereit sind.
26.06.2026
Live Redaktion

