OpenAI mobilisiert gesamte Chip-Industrie für KI-Training: AMD, NVIDIA, Intel, Microsoft und Broadcom setzen auf MRC
Es ist das eine, mit einem oder zwei großen Namen im KI-Segment zusammenzuarbeiten; OpenAI hat jedoch AMD, NVIDIA, Intel, Microsoft und Broadcom gewonnen, um das Training großer KI-Modelle zu beschleunigen.

Kurzfassung
Warum das wichtig ist
- Es ist das eine, mit einem oder zwei großen Namen im KI-Segment zusammenzuarbeiten; OpenAI hat jedoch AMD, NVIDIA, Intel, Microsoft und Broadcom gewonnen, um das Training großer KI-Modelle zu beschleunigen.
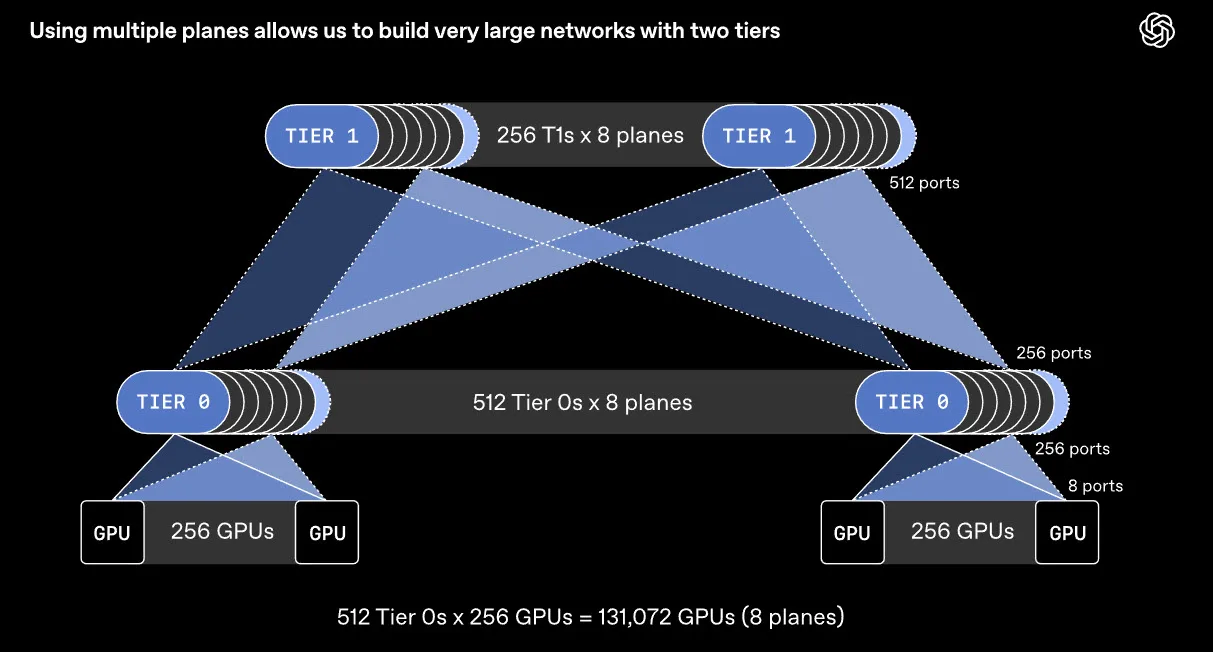
- Die neue Ankündigung für ein Supercomputer-Netzwerk, das darauf abzielt, das Training großer KI-Modelle zu beschleunigen.
- Zu diesem Zweck arbeiten AMD, Broadcom, Intel, Microsoft und NVIDIA mit dem Unternehmen zusammen, um ein neues Protokoll namens MRC (Multipath Reliable Connection) zu entwickeln, mit dem Ziel, die Netzwerkleistung und die Resilienz ßen Trainingsclustern zu verbessern.
SvyTech-Check
Redaktionelle Einordnung
Kernpunkt
Es ist das eine, mit einem oder zwei großen Namen im KI-Segment zusammenzuarbeiten; OpenAI hat jedoch AMD, NVIDIA, Intel, Microsoft und Broadcom gewonnen, um das Training großer KI-Modelle zu beschleunigen.
Warum relevant
OpenAI hat MRC heute über das OCP (Open Compute Project) veröffentlicht, um die breitere Nutzung des Protokolls bei KI-Unternehmen zu ermöglichen.
Einordnung
SvyTech ordnet die Meldung aus Wccftech als Teil des Themenfelds Technologie ein und verweist auf den Originalartikel, damit Leser Fakten, Quelle und Kontext nachvollziehen koennen.
Wir haben uns mit @AMD, @Broadcom, @Intel, @Microsoft und @NVIDIA verbündet, um Multipath Reliable Connection (MRC) zu veröffentlichen – ein neues offenes Netzwerkprotokoll, das große KI-Trainingsclustern hilft, schneller und zuverlässiger zu laufen und weniger GPU-Zeit zu verschwenden.
OpenAI hat MRC heute über das OCP (Open Compute Project) veröffentlicht, um die breitere Nutzung des Protokolls bei KI-Unternehmen zu ermöglichen. Das Problem, das die Einführung, ist der Datentransfer beim Training großer KI-Modelle.
Es wird festgestellt, dass selbst ein einziger verspäteter Transfer den gesamten Prozess unterbrechen und dazu führen kann, dass GPUs ungenutzt bleiben. Die Hauptursachen für diese Verzögerungen sind Netzwerkkongestion, Verbindungs- und Geräteausfälle. Je größer die Clustergröße ist, desto häufiger tritt dieses Problem auf.
Technik und Auswirkungen
Quellenprofil
Quelle und redaktionelle Angaben
- Quelle
- Wccftech
- Canonical
- https://wccftech.com/openai-accelerates-large-scale-ai-training-amd-nvidia-intel-microsoft-broadcom-mrc/
- Quell-URL
- https://wccftech.com/openai-accelerates-large-scale-ai-training-amd-nvidia-intel-microsoft-broadcom-mrc/
Aehnliche Inhalte
Verwandte Themen und interne Verlinkung
Weitere Artikel aus aehnlichen Themenfeldern, damit Leser direkt im selben Kontext weiterlesen koennen.

Chinesischer Unternehmer Cai Lei kämpft gegen die Zeit im Kampf gegen ALS
Cai Lei, ehemaliger stellvertretender Vorsitzender des chinesischen E-Commerce-Konzerns JD.com, widmet sich trotz seiner fortgeschrittenen ALS-Erkrankung, die ihm die Bewegungsfähigkeit und Sprechfähigkeit vollständig genommen hat, täglich 12 Stunden der Arbeit mit Augentracking-Technologie, um die medizinische Forschung zu beschleunigen. Der 48-jährige Unternehmer, der seit sieben Jahren mit der unheilbaren Krankheit kämpft und äften unterstützt wird, setzt sich mit außergewöhnlicher Anstrengung für die Einrichtung , die Förderung neuer Arzneimittelstudien und das Bewusstsein für die Krankheit ein, um zukünftigen Patienten Hoffnung zu geben.
21.06.2026